Block padding methods
Categories: cryptography
Block symmetric encryption algorithms operate on fixed size blocks of data. We will again assume a block size of 16 bytes (128 bits) for the examples. Of course, different algorithms might use different block sizes, but the same principles apply to any size block.
If you are encrypting a message in ECB or CBC [mode|blockmodes], it is necessary to ensure that the message is an exact multiple of the block length. This generally means that you need to pad the message data to the next block boundary. This is not difficult, but for historical reasons several standard padding methods have emerged. There is no real reason why we should need more than one standard padding method, but several methods exist and are widely used.
Zero Padding
Suppose your data is 45 bytes long. This data divides into 3 blocks, of size 16, 16 and 13 bytes. In the Zero Padding scheme, the final block is padded with zeros to make it up to 16 bytes. The total size of the encrypted data will therefore be 48 bytes.
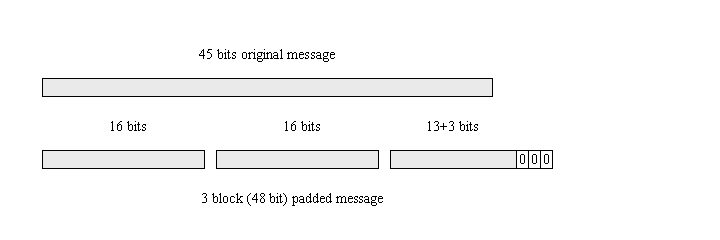
There is nothing in the ciphertext to indicate that the original plaintext was only 45 bytes long. The decrypted data will be 48 bytes long, and your application will need to worry about how much of that data is valid.
This isn't always a problem. Your data might be a fixed length (eg it is always 45 bytes long), or the data itself might have a length field. In some cases, for example if the data is a null terminated text string, the additional zero bytes at the end of the data might be ignored anyway.
Random Padding
This is similar to zero padding, but the bytes used to pad the message are assigned randomly selected values rather than always being set to zero.
With zero padding, an attacker knows that the final bytes of the plaintext are likely to be zeros. In principle, any information the attacker knows about the plaintext could be a help in cracking the encryption, and so it should be avoided. By using random values instead of zeros, there is no way of knowing the content of the padding bytes.
In real terms, this is probably not worth the effort. If you are using a strong encryption method the risk is very low.
PKCS7 Padding
An alternative form of padding is PKCS7. Instead of zeros or random data, the value of each byte is the number of padding bytes. In our case, with 3 padding bytes, then each of the padding bytes contains the value 3.

It is a simple matter for the decryptor to look at the final byte of the padded message, and discard that number of bytes from the decoded result. This means that you get the exact original message back, without any extra padding bytes.
It can also check that all the pad bytes have the same value, as a basic integrity check on the data. However, this check is rather weak. For example, if a decrypted message has a final byte of 1, then it will be recognised as a message with 1 pad byte and assumed to be correct. Suppose you fed completely random data into your decryptor, so that the output is also random. Approximately 1 in every 256 decoded messages would have a 1 as its final byte, and would therefore pass the integrity check despite being completely bogus. If you need to check the message integrity, include a [hash|hash] of the plaintext at the end of the message.
Finally, although this padding method has the advantage that it can automatically remove padding bytes on decryption, there is a small price to pay for this. This algorithm requires at least one pad byte. This means that if your data happens to fit into an exact number of blocks, then you need to add an entire extra block of padding. For example, if the data happens to be 48 bytes long, then you need to encrypt it as 64 bytes even though the final 16 bytes are all padding.
One and Zeroes Padding
Another alternative method is "one and zeroes" padding. In this method, the first pad byte is a 1, and the remaining pad bytes are 0. Once again it is a simple matter for the decryption process to discard the pad bytes. It simply counts back from the last byte until it finds a 1, and discards the excess bytes.

As with PKCS7, this algorithm offers weak integrity checking, and shares the disadvantage that an extra block of padding is added if the plaintext is an exact multiple of the block size. In fact these algorithms have almost identical characteristics, and the world would be no less rich if one or the other didn't exist - but they do exist and they are both used in various systems.
See also
- Symmetric encryption
- Applications of symmetric encryption
- Symmetric block ciphers
- Symmetric encryption algorithms
- Cryptographic modes
- Attacks on symmetric ciphers
- Cryptographic hashes
- Strong hashing functions
- Applications of hashes
- Common hash algorithms
- Attacks on hash algorithms
- Iterative hashes
- Message authentication codes
- Common MAC algorithms
- HMAC algorithm
- Key derivation
- Dictionary attacks on keys
- Key derivation using hash functions
- Salting
- Key derivation using random number generators
- Key derivation standards
Sign up to the Creative Coding Newletter
Join my newsletter to receive occasional emails when new content is added, using the form below:
Popular tags
555 timer abstract data type abstraction addition algorithm and gate array ascii ascii85 base32 base64 battery binary binary encoding binary search bit block cipher block padding byte canvas colour coming soon computer music condition cryptographic attacks cryptography decomposition decryption deduplication dictionary attack encryption file server flash memory hard drive hashing hexadecimal hmac html image insertion sort ip address key derivation lamp linear search list mac mac address mesh network message authentication code music nand gate network storage none nor gate not gate op-amp or gate pixel private key python quantisation queue raid ram relational operator resources rgb rom search sort sound synthesis ssd star network supercollider svg switch symmetric encryption truth table turtle graphics yenc