Cryptographic modes
Categories: cryptography
Symmetric encryption algorithms operate on fixed size blocks of data. Lets assume here that the block size is 16 bytes, a typical size. If we want to encrypt messages of more than 16 bytes (and of course we do!) then we need to define a way to do this. There are several standard ways of encrypting longer messages with block ciphers, and these are often referred to as cryptographic modes.
Electronic Code Book (ECB) Mode
Cryptography sometimes has a tendency to use grandiose, complex sounding names for rather simple concepts or algorithms. Electronic Code Book mode is a prime example. The technique is so obvious and simple it barely needs describing.
When encoding a message of greater than 16 bytes, simply split the plaintext messages into blocks of 16 bytes, and put each block through the encryption algorithm, using the same key each time.
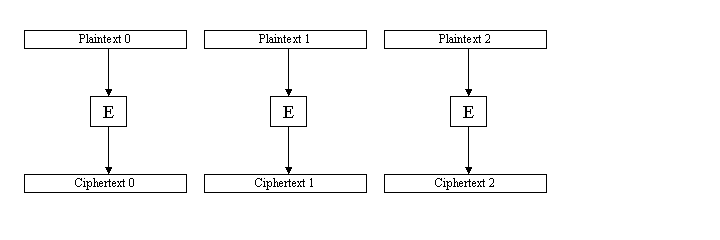
Thus the first 16 bytes of the plaintext are encrypted to form the first 16 bytes of the cipher text, the second 16 bytes of the plaintext are encrypted to form the second 16 bytes of the cipher text, etc...
Cipher Block Chaining (CBC) Mode
There is a possible problem with simple ECB mode. Suppose you encode a number of messages using the same key. If a particular 16 byte block appears more than once, anywhere in any message, it will always code to the same 16 bytes of cipher text.
If an attacker can somehow gain access to the plaintext and corresponding ciphertext for a number of messages, he can start building up a dictionary of known ciphertext blocks. It would be very difficult to build up a dictionary containing every possible ciphertext block, because the dictionary would very large (far bigger than anything we could possibly store on any existing computer). However, if the data is highly repetitive or structured, then a relatively small dictionary might capture almost all of the blocks which are frequently used, so that a large proportion of messages can be decoded.
At he time of writing, an ordinary household PC would be capable of storing a billion dictionary entries without too much trouble. In some cases this could partially break ECB mode encryption.
On solution to this problem is CBC (Cipher Block Chaining). In this mode, each plaintext block is XOR’ed with the previous cipher text block before being encrypted. This means that the cipher text for a particular block depends not only on the block itself, but also on everything which went before.
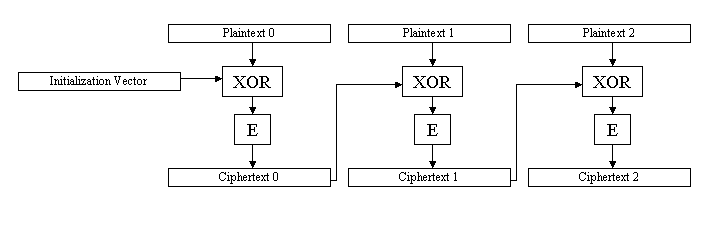
There is one remaining problem with this mode. What if two messages happen to start in exactly the same way (for example they include an identical data header)? Then the initial ciphertext blocks will be identical, up until the first different plaintext block occurs. While the encryption hasn't necessarily been broken, it is certainly leaking some information which an attacker might find useful in some circumstances.
Usually with CBC, a random Initial Value (IV) is injected into the first XOR operation. The same IV must also be used to start off the decryption. This ensures that identical or initially similar messages are always coded differently because they start from a different point.
The IV doesn't need to be secret. It is only intended as an extra random factor to disrupt dictionary attacks and similar. A different IV should be used each time - it can be random, or simply an incrementing value. It is usual to prepend the IV to the beginning of the ciphertext, so that the decryptor knows what to use. Knowledge of the IV is not a lot of help to anyone attacking the encryption scheme.
Other Modes
Various other modes, such as CFB, OFB and CTR modes are described in the section on stream ciphers.
See also
- Symmetric encryption
- Applications of symmetric encryption
- Symmetric block ciphers
- Symmetric encryption algorithms
- Block padding methods
- Attacks on symmetric ciphers
- Cryptographic hashes
- Strong hashing functions
- Applications of hashes
- Common hash algorithms
- Attacks on hash algorithms
- Iterative hashes
- Message authentication codes
- Common MAC algorithms
- HMAC algorithm
- Key derivation
- Dictionary attacks on keys
- Key derivation using hash functions
- Salting
- Key derivation using random number generators
- Key derivation standards
Sign up to the Creative Coding Newletter
Join my newsletter to receive occasional emails when new content is added, using the form below:
Popular tags
555 timer abstract data type abstraction addition algorithm and gate array ascii ascii85 base32 base64 battery binary binary encoding binary search bit block cipher block padding byte canvas colour coming soon computer music condition cryptographic attacks cryptography decomposition decryption deduplication dictionary attack encryption file server flash memory hard drive hashing hexadecimal hmac html image insertion sort ip address key derivation lamp linear search list mac mac address mesh network message authentication code music nand gate network storage none nor gate not gate op-amp or gate pixel private key python quantisation queue raid ram relational operator resources rgb rom search sort sound synthesis ssd star network supercollider svg switch symmetric encryption truth table turtle graphics yenc